Writing mutexes from scratch in Go
Did you know that in programming, threads have been locking in before it was cool?
A mutex (also known as a lock) is an object used to guarantee that only one thread can run a critical section of code at a time. The name “mutex” is short for mutual exclusion. Using a lock is straightforward in most popular backend languages:
// Java
Lock lock = new ReentrantLock();
lock.lock();
try {
// critical section
} finally {
lock.unlock();
}
# Python
import threading
lock = threading.Lock()
lock.acquire()
try:
# critical section
finally:
lock.release()
// Go
import "sync"
var mu sync.Mutex
mu.Lock()
// critical section
mu.Unlock()
A lock’s simplicity makes it broadly useful for protecting shared state in programs with many threads. But their implementations aren’t always simple.
In this blog post, I’ll show how to implement a lock several ways in Go, exploring how different performance tradeoffs can be addressed. All of the locks we implement will use the conventional interface:
type locker interface {
// Lock acquires the lock.
// If the lock is already held, it blocks until the lock is available.
Lock()
// Unlock releases the lock.
// It's a runtime error if the lock is not held by the caller.
Unlock()
}
Note: Some locks support an additional method named
TryLock()which attempts to acquire the lock without blocking. I’ll leave it as an exercise for the reader to extend the locks in this post with this method.
Spin lock: a first attempt
At the core of every mutex is some state used to track whether the mutex is held or not.
A naive way to implement a lock would be to store this in a boolean variable.
To acquire the lock, check if the variable is false, and if so, set it to true; otherwise, “busy-wait” and keep checking in a for/while loop until the lock is available.
To release the lock, set the variable to false.
In Go, this would look like:
// this lock implementation does not work!
type NaiveSpinLock struct {
state bool
}
func (l *NaiveSpinLock) Lock() {
for l.state != false {
// busy-wait
}
l.state = true
}
func (l *NaiveSpinLock) Unlock() {
l.state = false
}
This doesn’t work because there’s a data race making it possible for two threads to complete the Lock() method without ever calling Unlock().
The reason is that if two threads running concurrently each call the Lock() method, it’s possible that their instructions could be interleaved such that:
- Thread A finishes the for loop
- Thread B finishes the for loop
- Thread A sets
l.statetotrue - Thread B sets
l.statetotrue
After these steps, both threads believe they have exclusive ownership over the lock, which is clearly not the case. The scenario might sound rare, but it’s inevitable when a lock is under high contention (trying to be acquired by many threads). How do we fix this?
A working spin lock
To fix the race condition, we can use dedicated hardware instructions that tell the CPU to perform read-and-write operations atomically. In the code below, I use a “swap” instruction that stores a value at a memory address and returns the previous value stored:
import "sync/atomic"
type SpinLock struct {
state uint32 // 0 = unlocked, 1 = locked
}
func (l *SpinLock) Lock() {
for atomic.SwapUint32(&l.state, 1) == 1 {
// busy-wait
}
}
func (l *SpinLock) Unlock() {
atomic.StoreUint32(&l.state, 0)
}
Not too bad, right?
Inside the Lock() method, we perform a “swap” to store 1 in the state variable.
If swap returns 1, then the lock was already held, so we busy-wait and loop again.
If swap returns 0, then the lock wasn’t held, meaning we acquired it and can return.
A question you might ask: why does
Unlock()need to use an atomic operation? How would it be any different from writingl.state = 0? The reason has to do with the way that compilers and CPUs optimize the execution of instructions.In short: most assembly instructions that read or write to memory can be re-ordered – either by the compiler generating them, or by the CPU processing them – to improve performance for the 99.9% of situations where the exact order doesn’t affect the program behavior. For situations when the order does matter, special instructions can be used that guarantee memory ordering constraints. Code compiled using the functions from Go’s
sync/atomicpackage will use such instructions (like XCHGL for x86 machines or similar).The post Hardware Memory Models by Russ Cox goes into more depth about how and why instructions get reordered. I highly recommend giving it a read if you’re curious to learn more.
I wrote a small script to test SpinLock and ensure it provides mutual exclusion to the critical section.
It creates 32 goroutines (Go’s version of threads) that acquire and release the lock, incrementing a counter in between.
In addition to incrementing the counter, each goroutine spins for 10 microseconds to simulate some fake work.
func main() {
goroutines := 32
iterations := 10_000
work := time.Duration(10) * time.Microsecond
lock := &SpinLock{}
start := make(chan struct{})
var wg sync.WaitGroup
wg.Add(goroutines)
counter := 0
begin := time.Now()
for i := 0; i < goroutines; i++ {
go func() {
defer wg.Done()
<-start
for j := 0; j < iterations; j++ {
lock.Lock()
counter++
spin(work)
lock.Unlock()
}
}()
}
close(start)
wg.Wait()
elapsed := time.Since(begin)
fmt.Printf("%v,%d\n", elapsed, counter)
}
func spin(d time.Duration) {
if d <= 0 {
return
}
deadline := time.Now().Add(d)
for time.Now().Before(deadline) {
// busy-wait to simulate work inside the critical section
}
}
When I run the test script on my laptop with Go 1.25.5, it takes anywhere from 6 to 10 seconds, even though the total time spent on fake work was only 32 * 10,000 * 10µs = 3.2 seconds! That’s a pretty big difference – where’s all that extra time being spent?
The problem is that the Go runtime doesn’t know when to switch between the running goroutines.
Go’s runtime may let a thread busy-wait inside Lock() for up to 10ms before deciding “ok, this goroutine has been running for a long time - let’s pause it and let another goroutine run.”
Even in a language that used traditional threads rather than goroutines, you’d likely face the same issue with the operating system scheduler.
We can improve the spin lock’s efficiency by calling runtime.Gosched(). This tells Go: “feel free to switch to running another goroutine now.”
import "runtime"
// ...
func (l *SpinLock) Lock() {
for atomic.SwapUint32(&l.state, 1) == 1 {
runtime.Gosched()
}
}
Now, when I run the test script it only takes around 3.34 seconds. Much better!
This makes sense: whenever a thread can’t acquire the lock, it yields to another goroutine instead of looping more times, so goroutines spend less time busy-waiting. Only 3.34 - 3.2 = 0.14 seconds was spent on context switching between goroutines.
Actually, there’s one more small optimization we can make before moving on.
Currently each goroutine attempts to acquire the lock using atomic.SwapUint32(), which typically compiles down to a single assembly instruction.
This instruction dominates the busy-waiting time.
Since the instruction needs to both read and write to memory, the CPU needs to make sure it isn’t operating on any stale data when it gets executed.
This could require flushing write caches or buffers.
This makes it a comparatively expensive operation.
To optimize for the common case where the lock isn’t going to be acquired, we can instead try loading the value when we’re busy-waiting, and only attempt to acquire the lock (swap in a 1) if we recently saw a 0. By the time we perform the swap, it’s possible another thread has already grabbed the lock, so we wrap the whole process in a for loop to continue retrying:
func (l *SpinLock) Lock() {
for {
for atomic.LoadUint32(&l.state) == 1 {
runtime.Gosched()
}
if atomic.SwapUint32(&l.state, 1) == 0 {
return
}
}
}
In the literature this optimization is called test and test-and-set. When I tried the updated lock with my test script, the performance difference wasn’t significant, but I suspect it could be hardware dependent.
Measuring performance more rigorously
SpinLock seems to be fast.
So fast, in fact, that if we swap out the lock in the test script with the lock from Go’s standard library, sync.Mutex, we find that ours appears to run faster.
The test script increments the counter 320,000 times across 32 goroutines in 3.36 seconds when using the built-in sync.Mutex, and in 3.34 seconds when using our SpinLock.
Surely we must be missing something?
Let’s try timing the program’s performance using /usr/bin/time:
With SpinLock:
$ /usr/bin/time go run main.go
3.339245292s,320000
3.46 real 8.53 user 12.85 sys
With sync.Mutex:
$ /usr/bin/time go run main.go
3.368540708s,320000
3.43 real 3.74 user 0.59 sys
/usr/bin/time reports several forms of time. [1]
The first is the elapsed wall time (aka real time), which roughly matches the time reported by the test script.
The second is the amount of CPU time spent in user-mode code within the process.
The third is the amount of CPU time spent in the kernel within the process.
If we add up the second and third numbers, we get a total of 21.38 seconds and 4.33 seconds of CPU time spent by the program using the SpinLock and sync.Mutex respectively.
How are these numbers greater than the real time? They’re greater because a CPU has multiple cores. If a program uses two cores, it can perform up to 6 seconds of work within 3 seconds. My laptop has 10 cores, so 30 “CPU seconds” of work could be completed in 3 real seconds. That’s the power of parallel computing!
Unfortunately, this means that while SpinLock appears faster in this artificial benchmark, it was much less CPU efficient.
Most of that CPU time is being spent by the Go scheduler, pausing and continuing and rescheduling goroutines that are waiting for locks.
Locking with help from the operating system
We can reduce the time spent busy-waiting in userland (and even reduce the amount of system calls made by the Go runtime for scheduling goroutines) by adapting our mutex to use OS primitives for synchronization: specifically, I’ll be using the futex (short for “fast userspace mutex”). Eli Bendersky’s blog post Basics of Futexes provides a great overview of how and why futexes were added to Linux, as well as how to use them.
Futexes provide two main operations through system calls:
WAIT(addr, val)- if the value stored at addressaddrisval, put the current thread to sleepWAKE(addr, num)- wakes upnumthreads waiting on the addressaddr
By using a futex, we no longer have to rely on busy-waiting when we expect a lock to be held for a long time – we can just make a system call that essentially allows the thread to sleep, and the operating system will do the heavy lifting of tracking changes to memory addresses, and wake up the thread when it’s ready to acquire the lock.
Wikipedia details that there are APIs similar to the futex on other operating systems, but since they’re all a little different, I’ll just provide code for Linux in this post. To test it, I’m running the code in a Docker container since I’m on a different operating system (macOS).
I’ll implement this in Go as a struct named FutexLock.
I’m going to create two files: one for the Linux implementation (futex_lock_linux.go), and one for if the code runs on other operating systems (futex_lock_stub.go).
The code for non-Linux OSs is a placeholder - I keep it so my IDE can still type check my code on macOS.
//go:build !linux
package mu
type FutexLock struct {
WaitCount uint32
WakeCount uint32
}
func (m *FutexLock) Lock() { panic("futex mutex only supported on linux") }
func (m *FutexLock) Unlock() { panic("futex mutex only supported on linux") }
The comment at the top, //go:build !linux is a Go build constraint.
It says “this file should only be included when we’re compiling not on Linux.”
Onto the Linux implementation.
I’ll start by adding some helper functions for the FUTEX_WAIT and FUTEX_WAKE system calls described earlier:
//go:build linux
package mu
import (
"sync/atomic"
"unsafe"
"golang.org/x/sys/unix"
)
const (
FUTEX_WAIT = 0
FUTEX_WAKE = 1
FUTEX_PRIVATE_FLAG = 128
)
func futexWait(addr *uint32, val uint32) error {
_, _, errno := unix.Syscall6(
unix.SYS_FUTEX,
uintptr(unsafe.Pointer(addr)),
uintptr(FUTEX_WAIT|FUTEX_PRIVATE_FLAG),
uintptr(val),
0, 0, 0,
)
return errno
}
func futexWake(addr *uint32, num int) error {
_, _, errno := unix.Syscall6(
unix.SYS_FUTEX,
uintptr(unsafe.Pointer(addr)),
uintptr(FUTEX_WAKE|FUTEX_PRIVATE_FLAG),
uintptr(num),
0, 0, 0,
)
return errno
}
The golang.org/x/sys/unix package provides access to the raw system call interface of the underlying operating system.
The constants (FUTEX_WAIT, FUTEX_WAKE, FUTEX_PRIVATE_FLAG) I’ve included are from the futex.h header file in the Linux source code.
I’d import the header file directly if I was writing my code in C, but since we’re in Go, I just copied them by hand.
To implement the actual lock, we can base our first implementation on the existing spin lock.
It will look almost exactly the same, except instead of calling runtime.Gosched() (which is basically like telling the Go runtime that it is busy-waiting to switch to another goroutine – even though that goroutine might also be busy-waiting), it will call futexWait() (which is more like “parking” the goroutine until the lock becomes available again).
And likewise, when the lock is returned, we call futexWake() to wake up a single waiting goroutine.
Here’s how I’ve implemented this initial futex lock:
type FutexLock struct {
state uint32
}
func (m *FutexLock) Lock() {
for {
for atomic.LoadUint32(&m.state) == 1 {
futexWait(&m.state, 1)
}
if atomic.SwapUint32(&m.state, 1) == 0 {
return
}
}
}
func (m *FutexLock) Unlock() {
atomic.StoreUint32(&m.state, 0)
futexWake(&m.state, 1)
}
At this point I’m running the test script inside a docker container so I can use the Linux APIs.
I’ve retested all three locks we have (SpinLock, FutexLock, and the built-in sync.Mutex), in docker to ensure the results are comparable:
| Lock | Real time | User time | System time |
|---|---|---|---|
| SpinLock | 3.27s | 16.06s | 4.15s |
| FutexLock | 3.91s | 9.97s | 1.26s |
| sync.Mutex | 3.29s | 8.81s | 0.58s |
This is a substantial improvement! There is still some more performance we can eke out though.
Notice that Unlock() always calls futexWake().
This is inefficient because it’s possible there aren’t any threads waiting to acquire the lock.
This may happen frequently if the lock is only acquired for very short periods.
To that end, we ought to track not just whether a lock is held, but whether there are threads waiting on the lock (i.e. whether the lock has waiters).
Here’s an updated implementation, where the lock’s state will take on up to three values: 0, 1, or 2.
0 means the lock isn’t held, 1 means the lock is held with no waiters, and 2 means the lock is held, possibly with waiters.
The main idea is, if a lock isn’t held, the first time it’s acquired the state will be set to 1.
If the lock is released shortly thereafter, since the previous state was 1, no threads need to be woken up, so we save a syscall.
func (m *FutexLock) Lock() {
// Fast path: the lock isn't held
if atomic.CompareAndSwapUint32(&m.state, 0, 1) {
return
}
// Slow path
for {
// Try to acquire the lock, and see if it's already held.
// If previous value was 0, we acquired the lock and leave it in contended state (2).
if atomic.SwapUint32(&m.state, 2) == 0 {
return
}
// Sleep while contended.
_ = futexWait(&m.state, 2)
}
}
func (m *FutexLock) Unlock() {
prev := atomic.SwapUint32(&m.state, 0)
if prev == 0 {
panic("unlock of unlocked FutexLock")
}
// If it was uncontended (1), no one should be sleeping.
if prev == 1 {
return
}
// If contended (2): wake one.
_ = futexWake(&m.state, 1)
}
It is possible the state could store 2 without any threads currently waiting, for example:
- Thread A acquires the lock, setting state to 1
- Thread B tries to acquire the lock, failing the fast path, about to begin the slow path
- Thread A releases the lock, setting state to 0
- Thread B swaps in a 2, and acquires the lock since the previous state was 0
So unneeded futexWake() calls can still happen, but it’s the minority of cases.
It’s possible to tweak this state machine in other ways, but it requires some care to avoid potential deadlock - Ulrich Drepper’s paper Futexes Are Tricky goes into a lot more detail.
The implementation I’ve used above is based on one in the paper.
Now when we test our lock, FutexLock’s performance is much closer to sync.Mutex!
| Lock | Real time | User time | System time |
|---|---|---|---|
| SpinLock | 3.27s | 16.06s | 4.15s |
| FutexLock | 3.91s | 9.97s | 1.26s |
| FutexLock (improved) | 3.30s | 9.79s | 0.51s |
| AdaptiveFutexLock | 3.69s | 9.77s | 1.10s |
| sync.Mutex | 3.29s | 8.81s | 0.58s |
Bringing back spinning
Futexes solve the issue of the excess CPU use that came with spin-locking.
But there is a cost, which is that every goroutine that can’t acquire a lock immediately has to wait itself using a futex.
A syscall isn’t as fast as a dedicated assembly instruction though.
In the time it took to perform the one syscall, it’s possible that dozens of atomic CompareAndSet operations could have been performed.
To reconcile this, many lock implementations will try to spin for a short amount of time before giving up and using the futex API to go to sleep.
We can incorporate this into our FutexLock straightforwardly:
func (m *FutexLock) Lock() {
// Fast path: the lock isn't held
if atomic.CompareAndSwapUint32(&m.state, 0, 1) {
return
}
// Medium path: spin a little before sleeping.
for i := 0; i < 30; i++ {
if atomic.LoadUint32(&m.state) == 0 {
if atomic.CompareAndSwapUint32(&m.state, 0, 1) {
return
}
}
// A cheap pause to allow other goroutines to run
runtime.Gosched()
}
// Slow path
for {
// Try to acquire the lock, and see if it's already held.
// If previous value was 0, we acquired the lock and leave it in contended state (2).
if atomic.SwapUint32(&m.state, 2) == 0 {
return
}
// Sleep while contended.
_ = futexWait(&m.state, 2)
}
}
If we run our regular test we won’t see a significant difference between this lock implementation and the previous one. To notice the difference better, we have to tweak the test scenario. I’ve changed my test to run with 320 goroutines (10x), each trying to acquire the lock 100,000 times (10x), but with 0 sleeping while holding the lock. That means as soon as a lock is acquired, it can also be released. I’ve distinguished between the different versions of the locks we implemented using version suffixes:
| Lock | Real time | User time | System time |
|---|---|---|---|
| sync.Mutex | 2.07s | 10.46s | 0.56s |
| SpinLockV1 | 0.78s | 8.19s | 1.30s |
| SpinLockV2 | 0.69s | 7.94s | 1.14s |
| FutexLockV1 | 13.30s | 13.81s | 95.17s |
| FutexLockV2 | 2.58s | 9.28s | 6.17s |
| FutexLockV3 | 0.69s | 8.07s | 1.24s |
And here are the results graphed with a logarithmic scale:
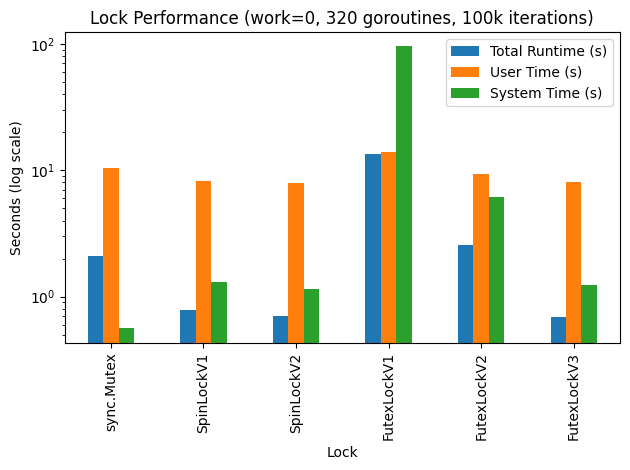
From this we can see that relative to the previous versions, adaptive spinning helps a lot when a lock is under frequent swapping.
By including it, FutexLock (v3) is able to stay competitive with the SpinLock, which turns out to perform very well in this scenario compared to the built-in sync.Mutex!
Open questions
There’s a lot more to building locks than I could cover, but I think I’m going to finish the post here. I’ve published all of the code from this post on GitHub, so check it out if you’d like to toy around with lock implementations on your own. (It includes one more implementation I didn’t have time to fit in called a ticket lock).
Here are some questions I had left after writing that I didn’t have time to dig into further, but would be interested to explore further:
- What would be the ideal suite of unit tests and benchmarks for testing a lock implementation? How did the Go team end up deciding what performance criteria was important to meet for
sync.Mutex? Do they use any benchmarks? - How does Linux’s
futexsyscall work under the hood? What does the kernel do at a low level to monitor individual memory addresses? What data structures are used to track the waiting threads? What’s preventing something likefutexfrom being implemented in userland? - How does Linux’s
futexsyscall differ from the WindowsWaitOnAddressAPI or the macOSos_sync_wait_on_addressAPI? - How does the built-in lock implementation of Go differ from the one that comes in Rust? Python? Java?
- How is fairness of threads trying to acquire a lock guaranteed? Does the kernel use queues to track the order of threads waiting on an address? How about the Go runtime with sync.Mutex?
- What does it look like to prove that lock algorithms are correct? What model checking languages work best for these kinds of algorithms? (Fuzz testing is cool, but provably safe software is even better.)
- Is there potential to build a more efficient lock by having a lock change its default behavior (like how long it spins for, whether it tracks waiters or not, etc.) based on how much contention it’s seeing, or how many processors the underlying machine has?
- How does the implementation of
sync.RWMutexdiffer fromsync.Mutex? What kind of algorithms are used for readers-writer locks?