Building thread-safe abstractions in Java versus Go
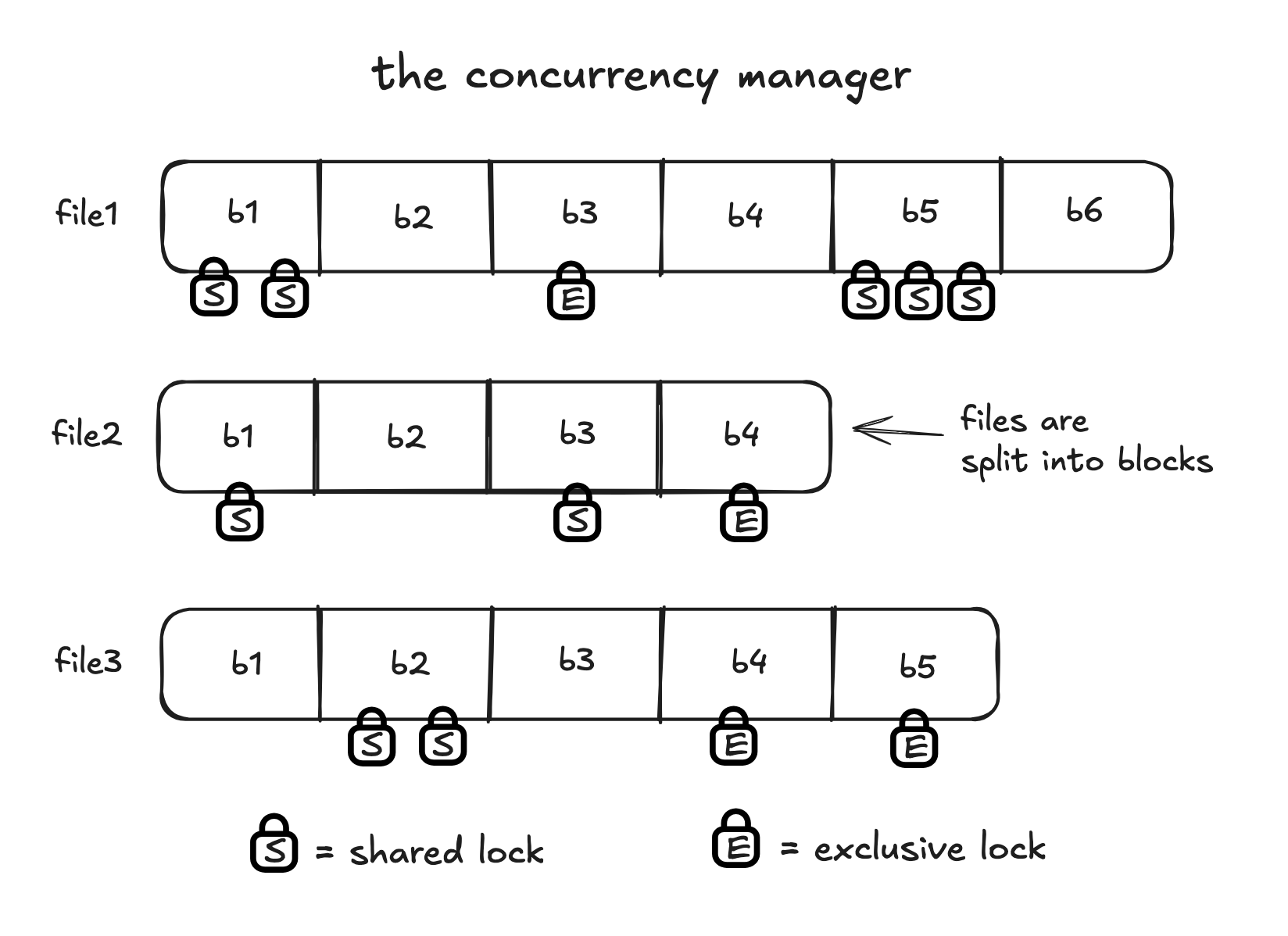
A visualization of the concurrency manager subsystem in SimpleDB, relevant for the code in the second half of the post.
Recently, I started studying about how databases are implemented by reading the book Database Design and Implementation (2020). I’m only part ways through it, but the text provides a solid walkthrough of the subsystems that go into a traditional relational database, from memory and recovery management to query processing and planning; and I’m enjoying my time going through it.
Something I especially appreciate is that the text includes a toy database implementation named SimpleDB (consisting of 12KLOC and 150+ Java classes) that demonstrates the all of the major pieces of a database system with working tests.
To build a working understanding and get more comfortable with Go (the systems programming language from Google), I decided to try my hand at porting the database implementation from Java to Go. While the languages differ in a number of major ways – for example, Java lacks pointers and is more object-oriented than Go – they also share a lot of features, like garbage collection and strong typing; so I felt like it wouldn’t be too hard to translate the code.
In this post, I’ll dive into how I translated some pieces of the SimpleDB implementation from Java into Go, and how I navigated the differences between the concurrency and synchronization primitives the languages provide.
Part 1: Building a File Manager
First, I’ll start with a simple case where translating thread-safe Java code into Go isn’t too hard.
SimpleDB stores all data on the file system at the end of the day - but we we want to: (1) minimize file operations, and (2) avoid multiple threads performing conflicting reads and writes to underlying files.
To achieve this, it has a class named FileMgr for providing access to files.
Here’s an abbreviated Java implementation of the class:
package simpledb.file;
import java.io.*;
import java.nio.*;
import java.util.*;
public class FileMgr {
private Map<String,RandomAccessFile> openFiles = new HashMap<>();
public synchronized void read(String filename, ByteBuffer b, int offset) {
try {
RandomAccessFile f = getFile(filename);
f.seek(offset);
f.getChannel().read(b);
} catch (IOException e) {
throw new RuntimeException("cannot read file " + filename);
}
}
public synchronized void write(String filename, ByteBuffer b, int offset) {
try {
RandomAccessFile f = getFile(filename);
f.seek(offset);
f.getChannel().write(b);
} catch (IOException e) {
throw new RuntimeException("cannot write file" + filename);
}
}
public int length(String filename) {
try {
RandomAccessFile f = getFile(filename);
return (int)(f.length());
} catch (IOException e) {
throw new RuntimeException("cannot access " + filename);
}
}
private RandomAccessFile getFile(String filename) throws IOException {
RandomAccessFile f = openFiles.get(filename);
if (f == null) {
File dbTable = new File(filename);
f = new RandomAccessFile(dbTable, "rws");
openFiles.put(filename, f);
}
return f;
}
}
The class internally stores a map of file names to open files, and provides a handful of public methods like read(), write(), and length() for reading and writing to those files.
(In the actual implementation, there are a few more options and methods, but I’ve tried to simplify the example).
To synchronize access and prevent threads from performing conflicting writes or reads, many of the methods using the open files are marked as synchronized.
In Java, the synchronized keyword ensures that it’s not possible for two invocations of the methods on the same object to interleave:
“When one thread is executing a synchronized method for an object, all other threads that invoke synchronized methods for the same object block (suspend execution) until the first thread is done with the object.” - The Java Documentation
By synchronizing access to the openFiles map, the implementation avoids possible interleavings like the following:
- Thread A calls
read("file1", buffer1, 0) - Thread A runs
f = getFile(..)andf.seek(0) - Thread B calls
write("file1", buffer2, 40) - Thread B runs
f = getFile(..)andf.seek(40)(referring to the same file as thread A) - Thread B runs
f.getChannel().write(b)and exits the method - Thread A runs
f.getChannel().read(b)and exits the method
In the above example, thread A intended to read bytes from the beginning of the file, but the way the operations interleave cause it to end up reading bytes after byte 40.
The Go version of FileManager
This kind of concurrency control, where you just want to ensure sections of code aren’t run at the same time, is easy to implement in Go.
At least, it’s common enough that it’s shown in the main Go tutorial.
The trick is to use a sync.Mutex (or sync.RWMutex) to guard the critical section(s):
package main
import (
"fmt"
"io"
"os"
"sync"
)
type FileMgr struct {
openFiles map[string]*os.File
mu sync.RWMutex
}
func NewFileMgr() *FileMgr {
return &FileMgr{
openFiles: make(map[string]*os.File),
}
}
func (fm *FileMgr) Close() {
fm.mu.Lock()
defer fm.mu.Unlock()
for _, f := range fm.openFiles {
f.Close()
}
fm.openFiles = nil
}
func (fm *FileMgr) Read(filename string, buf []byte, offset int64) error {
f, err := fm.getFile(filename)
if err != nil {
return err
}
if _, err = f.ReadAt(buf, offset); err != nil {
if err != io.EOF {
return fmt.Errorf("cannot read file %s: %w", filename, err)
}
}
return nil
}
func (fm *FileMgr) Write(filename string, buf []byte, offset int64) error {
f, err := fm.getFile(filename)
if err != nil {
return err
}
if _, err := f.WriteAt(buf, offset); err != nil {
return fmt.Errorf("cannot write file %s: %w", filename, err)
}
return nil
}
func (fm *FileMgr) Length(filename string) (int64, error) {
f, err := fm.getFile(filename)
if err != nil {
return 0, err
}
info, err := f.Stat()
if err != nil {
return 0, fmt.Errorf("cannot stat file %s: %w", filename, err)
}
return info.Size(), nil
}
func (fm *FileMgr) getFile(filename string) (*os.File, error) {
fm.mu.RLock()
f, ok := fm.openFiles[filename]
fm.mu.RUnlock()
if ok {
return f, nil
}
// If file isn't open, acquire write lock
fm.mu.Lock()
defer fm.mu.Unlock()
// Double-check after acquiring write lock
if f, ok := fm.openFiles[filename]; ok {
return f, nil
}
f, err := os.OpenFile(filename, os.O_RDWR|os.O_CREATE|os.O_SYNC, 0644)
if err != nil {
return nil, fmt.Errorf("cannot open file %s: %w", filename, err)
}
fm.openFiles[filename] = f
return f, nil
}
In the Go translation of FileMgr, I’ve moved where some of the synchronization happens so it’s just happening inside the public Close() function and private getFile() function.
We call mu.Lock() to obtain an exclusive lock, and mu.Unlock() will release the lock. (The defer keyword tells Go to run the code in the Unlock() call whenever the function exits).
This ensures that the openFiles map is never accessed by multiple goroutines at the same time.1
A goroutines is Go’s version of a thread.
We don’t have to do anything to synchronize access to the individual files because the Go os.File type is already designed to be safe for concurrent use by multiple goroutines.
Part 2: Building a Lock Table
Now, let’s dive into a more complex example.
To set the stage, recall that SimpleDB is modeled after a traditional relational database. To support multiple concurrent transactions that perform a mix of reads and writes, SimpleDB has a dedicated subsystem called a concurrency manager which is responsible for ensuring transactions appear to work as if they’re isolated from each other.
For example, if one transaction updates a row in the database but that transaction hasn’t been committed, other transactions shouldn’t be able to see that partial change; this kind of error would be called a dirty read. Some other examples of data inconsistencies that can occur are non-repeatable reads and phantom reads.
The concurrency manager prevents conflicting data accesses through a form of pessimistic concurrency control - and the main data structure it uses is a lock table. A lock table keeps track of which pieces of data have been locked by transactions (i.e. given access exclusive) for reading or writing. For this blog post, I’m going to assume we’re locking access to files. (But the lock table could also be used to lock access to blocks, which are fixed-sized file parts, or even individual rows in a table).
When a transaction wants to read a row from the table, it first identifies which file the table’s data is in, and requests a shared lock (or SLock) for that file from the lock table. When a transaction wants to write a row to the table, it again identifies which file the table’s data is in, and requests an exclusive lock (or XLock) for that file from the lock table.
The difference between a shared lock and and exclusive lock is that multiple transactions can hold shared locks to the same file without conflicts, but an exclusive lock can only be held by a single file at a time. It’s not allowed for shared and exclusive locks to be held on the same file at the same time.
So, what does the LockTable implementation look like in practice?
Well, feast your eyes on this Java class:
package simpledb.tx.concurrency;
import java.util.*;
class LockTable {
private static final long MAX_TIME = 10000; // 10 seconds
private Map<String,Integer> locks = new HashMap<String,Integer>();
public synchronized void sLock(String filename) {
try {
long timestamp = System.currentTimeMillis();
while (hasXlock(filename) && !waitingTooLong(timestamp)) {
wait(MAX_TIME);
}
if (hasXlock(filename)) {
throw new LockAbortException();
}
int val = getLockVal(filename); // will not be negative
locks.put(filename, val+1);
} catch(InterruptedException e) {
throw new LockAbortException();
}
}
synchronized void xLock(String filename) {
try {
long timestamp = System.currentTimeMillis();
while (hasOtherLocks(filename) && !waitingTooLong(timestamp)) {
wait(MAX_TIME);
}
if (hasOtherLocks(filename)) {
throw new LockAbortException();
}
locks.put(filename, -1);
} catch(InterruptedException e) {
throw new LockAbortException();
}
}
synchronized void unlock(String filename) {
int val = getLockVal(filename);
if (val > 1) {
locks.put(filename, val-1);
} else {
locks.remove(filename);
notifyAll();
}
}
private boolean hasXlock(String filename) {
return getLockVal(filename) < 0;
}
private boolean hasOtherLocks(String filename) {
return getLockVal(filename) != 0;
}
private boolean waitingTooLong(long starttime) {
return System.currentTimeMillis() - starttime > MAX_TIME;
}
private int getLockVal(String filename) {
Integer ival = locks.get(filename);
return (ival == null) ? 0 : ival.intValue();
}
}
Not too bad, right?
The class stores a mapping of files to numbers inside a class field named locks.
Here’s what the numbers mean:
- If a file’s number is 0, there are no locks on it.
- If a file’s number is -1, there’s an exclusive lock on it.
- If a file’s number is positive, there’s that many shared locks on it.
When a caller tries to obtain one of the locks, if it’s not possible to obtain the lock, the implementation tells the thread to wait().2
For example, if a transaction is trying to obtain an XLock for file A, but another transaction has already has an SLock on file A, then the transaction must wait until the SLock on file A is released.
The wait() method is passed a timeout value, so the thread will only wait for a limited amount of time before giving up and throwing an exception.
If you glance over to the unlock() method implementation, you’ll see that when a file is unlocked, it notifies all waiting threads via notifyAll().34
How would we implement this kind of data structure (with the thread waiting and resuming functionality) in Go?
Go attempt 1: sync.Cond
One idea I had was to use a type from the Go standard library: sync.Cond.
This type represents a conditional variable, and methods like Wait() and Broadcast() can be used to suspend the calling goroutine or wake any waiting goroutines, respectively.
Unfortunately, sync.Cond didn’t seem like the right tool for the job.
The main issue was that there’s no simple way to wait for the condition variable with a timeout.
We need a timeout mechanism so that even if two or more transactions are deadlocked, we can return control back to the clients connecting to the database.
In this GitHub issue, the Go maintainers advise that condition variables are “generally not the right thing to use in Go”, and channels should be used instead.
An alternative approach might have been to use sync.Cond but change the broader implementation strategy so that the LockTable immediately returns an error if it can’t acquire a lock, rather than making the caller wait.
But I think this might come with its own trade-offs, and I wanted to keep the implementation as close to the Java version as possible, so I decided to try something different.
Go attempt 2: synchronization using channels
It turns out that channels are super powerful in Go5, and they offer a lot of flexibility for scheduling goroutines. If you’re not familiar with Go, channels are a first class datatype for sending and receiving values between goroutines. In our case, we can use channels purely as a way to synchronize behavior between goroutines.
The strategy I employed was to create a channel for each file that can be locked.
Suppose a goroutine wants to acquire its own exclusive lock by calling XLock() and another goroutine already has an exclusive lock on the file.
In that case, it will wait on the channel.
When the file is unlocked, the channel can be closed, which will trigger all goroutines waiting on the channel to resume.6
Thus, the goroutine that called XLock() will wake up and try to acquire the lock again.
Here’s the implementation:
package main
import (
"errors"
"sync"
"time"
)
const maxWaitTime = 10 * time.Second
type LockTable struct {
mu sync.Mutex
locks map[string]int
waiters map[string]chan struct{}
}
func NewLockTable() *LockTable {
return &LockTable{
locks: make(map[string]int),
waiters: make(map[string]chan struct{}),
}
}
func (lt *LockTable) SLock(filename string) error {
lt.mu.Lock()
start := time.Now()
// While an XLock is still held on this file...
for lt.locks[filename] == -1 {
ch := lt.getOrCreateWaitChannel(filename)
lt.mu.Unlock()
if time.Since(start) > maxWaitTime {
return errors.New("lock abort error")
}
// Wait on the channel with a timeout
select {
case <-ch:
// Continue when the lock is released
case <-time.After(maxWaitTime):
return errors.New("lock abort error")
}
lt.mu.Lock()
}
val := lt.locks[filename] // will not be negative
lt.locks[filename] = val + 1
lt.mu.Unlock()
return nil
}
func (lt *LockTable) XLock(filename string) error {
lt.mu.Lock()
start := time.Now()
// While any lock is still held on this file...
for lt.locks[filename] != 0 {
ch := lt.getOrCreateWaitChannel(filename)
lt.mu.Unlock()
if time.Since(start) > maxWaitTime {
return errors.New("lock abort error")
}
// Wait on the channel with a timeout
select {
case <-ch:
// Continue when the lock is released
case <-time.After(maxWaitTime):
return errors.New("lock abort error")
}
lt.mu.Lock()
}
lt.locks[filename] = -1
lt.mu.Unlock()
return nil
}
func (lt *LockTable) Unlock(filename string) {
lt.mu.Lock()
defer lt.mu.Unlock()
val := lt.locks[filename]
if val > 1 {
lt.locks[filename] = val - 1
} else {
delete(lt.locks, filename)
}
// Signal all goroutines waiting for this file (and remove the channel)
if ch, exists := lt.waiters[filename]; exists {
close(ch)
delete(lt.waiters, filename)
}
}
func (lt *LockTable) getOrCreateWaitChannel(filename string) chan struct{} {
if ch, exists := lt.waiters[filename]; exists {
return ch
}
ch := make(chan struct{})
lt.waiters[filename] = ch
return ch
}
Synchronization within the XLock() and SLock() methods is a little more involved, because we want to ensure the locks map is only accessed when the current goroutine has exclusive access to it – but we can’t hold onto the lock while we’re waiting for one of the channels.
So the implementation has to do a little bit of work to unlock and re-lock during the loop to keep everything working smoothly.
The most important lines are here:
select {
case <-ch:
// Continue when the lock is released
case <-time.After(maxWaitTime):
return errors.New("lock abort error")
}
The select statement tells the current goroutine to wait until one of the conditions is ready:
case <-ch:will run when the channel is closed (or when a message is sent to the channel)case <-time.After(maxWaitTime):will run after 10 seconds has passed
By doing this, we can bound the amount of time we’re waiting for a lock, and return an error if we can’t acquire it.
I think it’s pretty cool how channels can be used to build up abstractions like this.
Testing out the solution
When you’re building algorithms that deal with concurrency, you really have to test out your code to see whether it works.
Here’s some code I wrote to stress test the lock table. It spins up a hundred goroutines, each of which creates a transaction that acquires and releases a single shared or exclusive lock:
// Simulate a transaction trying to acquire and release locks
func simulateTransaction(id int, lt *LockTable, filename string, wg *sync.WaitGroup) {
defer wg.Done()
// Randomly decide whether to request a shared or exclusive lock
if rand.Intn(2) == 0 {
// Try acquiring a shared lock
log.Printf("Transaction %d: Trying to acquire SLock on %v\n", id, filename)
err := lt.SLock(filename)
if err != nil {
log.Printf("Transaction %d: Failed to acquire SLock on %v: %v\n", id, filename, err)
return
}
log.Printf("Transaction %d: Acquired SLock on %v\n", id, filename)
// Simulate work with the lock
time.Sleep(time.Duration(rand.Intn(20)) * time.Millisecond)
// Release the lock
lt.Unlock(filename)
log.Printf("Transaction %d: Released SLock on %v\n", id, filename)
} else {
// Try acquiring an exclusive lock
log.Printf("Transaction %d: Trying to acquire XLock on %v\n", id, filename)
err := lt.XLock(filename)
if err != nil {
log.Printf("Transaction %d: Failed to acquire XLock on %v: %v\n", id, filename, err)
return
}
log.Printf("Transaction %d: Acquired XLock on %v\n", id, filename)
// Simulate work with the lock
time.Sleep(time.Duration(rand.Intn(20)) * time.Millisecond)
// Release the lock
lt.Unlock(filename)
log.Printf("Transaction %d: Released XLock on %v\n", id, filename)
}
}
func main() {
log.SetFlags(log.Ltime | log.Lmicroseconds)
rand.Seed(time.Now().UnixNano())
lt := NewLockTable()
filenames := []string{
"file1",
"file2",
"file3",
}
var wg sync.WaitGroup
numTransactions := 100
// Spin up a bunch of transactions
for i := 1; i <= numTransactions; i++ {
wg.Add(1)
blk := filenames[rand.Intn(len(filenames))]
go simulateTransaction(i, lt, blk, &wg)
// Spread out the transactions to better simulate a real workload
time.Sleep(time.Duration(rand.Intn(5)) * time.Millisecond)
}
wg.Wait()
fmt.Println("Done!")
}
In practice, transactions in the database system may acquire locks on multiple files (and this can result in complex deadlock scenarios) - but this simplified stress test is still useful to validate that in the happy path, we’re able to provide exclusive and shared access to resources without goroutines hanging due to bugs.
Here’s the output from one of the runs:
16:57:40.674684 Transaction 1: Trying to acquire SLock on file1
16:57:40.674936 Transaction 1: Acquired SLock on file1
16:57:40.677057 Transaction 2: Trying to acquire XLock on file1
16:57:40.679339 Transaction 3: Trying to acquire SLock on file3
16:57:40.679398 Transaction 3: Acquired SLock on file3
16:57:40.680637 Transaction 4: Trying to acquire XLock on file1
16:57:40.683899 Transaction 6: Trying to acquire SLock on file3
16:57:40.683966 Transaction 5: Trying to acquire SLock on file3
16:57:40.684032 Transaction 6: Acquired SLock on file3
16:57:40.684039 Transaction 5: Acquired SLock on file3
16:57:40.684044 Transaction 5: Released SLock on file3
16:57:40.686260 Transaction 7: Trying to acquire SLock on file2
16:57:40.686301 Transaction 7: Acquired SLock on file2
16:57:40.690894 Transaction 8: Trying to acquire XLock on file3
16:57:40.692564 Transaction 7: Released SLock on file2
16:57:40.692986 Transaction 9: Trying to acquire SLock on file3
16:57:40.693007 Transaction 9: Acquired SLock on file3
16:57:40.694066 Transaction 2: Acquired XLock on file1
16:57:40.694125 Transaction 1: Released SLock on file1
16:57:40.695186 Transaction 6: Released SLock on file3
16:57:40.695317 Transaction 10: Trying to acquire SLock on file1
16:57:40.696549 Transaction 12: Trying to acquire SLock on file3
16:57:40.696570 Transaction 3: Released SLock on file3
16:57:40.696593 Transaction 12: Acquired SLock on file3
16:57:40.696596 Transaction 11: Trying to acquire SLock on file1
16:57:40.699798 Transaction 13: Trying to acquire SLock on file2
16:57:40.699839 Transaction 13: Acquired SLock on file2
16:57:40.700768 Transaction 12: Released SLock on file3
16:57:40.700820 Transaction 14: Trying to acquire XLock on file2
16:57:40.705107 Transaction 16: Trying to acquire XLock on file2
16:57:40.705121 Transaction 15: Trying to acquire XLock on file3
16:57:40.708359 Transaction 13: Released SLock on file2
16:57:40.708505 Transaction 14: Acquired XLock on file2
16:57:40.708521 Transaction 2: Released XLock on file1
16:57:40.708529 Transaction 4: Acquired XLock on file1
16:57:40.709304 Transaction 18: Trying to acquire XLock on file2
16:57:40.709327 Transaction 17: Trying to acquire SLock on file2
16:57:40.712449 Transaction 9: Released SLock on file3
16:57:40.712507 Transaction 15: Acquired XLock on file3
16:57:40.713599 Transaction 19: Trying to acquire XLock on file3
16:57:40.716664 Transaction 14: Released XLock on file2
16:57:40.716767 Transaction 16: Acquired XLock on file2
16:57:40.717847 Transaction 20: Trying to acquire XLock on file1
16:57:40.719105 Transaction 21: Trying to acquire SLock on file1
16:57:40.722334 Transaction 22: Trying to acquire XLock on file3
16:57:40.723546 Transaction 23: Trying to acquire XLock on file1
16:57:40.723659 Transaction 15: Released XLock on file3
16:57:40.723684 Transaction 22: Acquired XLock on file3
16:57:40.725051 Transaction 19: Acquired XLock on file3
16:57:40.725122 Transaction 22: Released XLock on file3
16:57:40.725700 Transaction 4: Released XLock on file1
16:57:40.725732 Transaction 11: Acquired SLock on file1
16:57:40.725757 Transaction 21: Acquired SLock on file1
16:57:40.725809 Transaction 10: Acquired SLock on file1
16:57:40.725848 Transaction 24: Trying to acquire XLock on file3
16:57:40.727133 Transaction 25: Trying to acquire XLock on file3
16:57:40.728080 Transaction 11: Released SLock on file1
16:57:40.729095 Transaction 16: Released XLock on file2
16:57:40.729134 Transaction 17: Acquired SLock on file2
16:57:40.730392 Transaction 26: Trying to acquire XLock on file1
16:57:40.732181 Transaction 21: Released SLock on file1
16:57:40.734725 Transaction 28: Trying to acquire XLock on file2
16:57:40.734757 Transaction 27: Trying to acquire XLock on file1
16:57:40.738251 Transaction 29: Trying to acquire SLock on file1
16:57:40.738287 Transaction 10: Released SLock on file1
16:57:40.738307 Transaction 23: Acquired XLock on file1
16:57:40.739340 Transaction 17: Released SLock on file2
16:57:40.739379 Transaction 18: Acquired XLock on file2
16:57:40.741456 Transaction 19: Released XLock on file3
16:57:40.741524 Transaction 8: Acquired XLock on file3
16:57:40.741597 Transaction 30: Trying to acquire XLock on file3
16:57:40.743704 Transaction 18: Released XLock on file2
16:57:40.743753 Transaction 32: Trying to acquire SLock on file2
16:57:40.743785 Transaction 28: Acquired XLock on file2
16:57:40.743811 Transaction 31: Trying to acquire SLock on file3
16:57:40.747316 Transaction 28: Released XLock on file2
16:57:40.747352 Transaction 32: Acquired SLock on file2
16:57:40.747863 Transaction 33: Trying to acquire SLock on file2
16:57:40.747902 Transaction 33: Acquired SLock on file2
16:57:40.749088 Transaction 34: Trying to acquire SLock on file2
16:57:40.749260 Transaction 34: Acquired SLock on file2
16:57:40.749491 Transaction 23: Released XLock on file1
16:57:40.749519 Transaction 27: Acquired XLock on file1
16:57:40.750012 Transaction 33: Released SLock on file2
16:57:40.751480 Transaction 34: Released SLock on file2
16:57:40.752213 Transaction 35: Trying to acquire XLock on file1
16:57:40.752407 Transaction 32: Released SLock on file2
16:57:40.756748 Transaction 37: Trying to acquire SLock on file3
16:57:40.756810 Transaction 36: Trying to acquire XLock on file1
16:57:40.759961 Transaction 8: Released XLock on file3
16:57:40.759988 Transaction 25: Acquired XLock on file3
16:57:40.760884 Transaction 38: Trying to acquire SLock on file3
16:57:40.761704 Transaction 27: Released XLock on file1
16:57:40.761721 Transaction 35: Acquired XLock on file1
16:57:40.762935 Transaction 39: Trying to acquire XLock on file3
16:57:40.765408 Transaction 41: Trying to acquire XLock on file3
16:57:40.765424 Transaction 40: Trying to acquire SLock on file1
16:57:40.765469 Transaction 38: Acquired SLock on file3
16:57:40.765469 Transaction 25: Released XLock on file3
16:57:40.765493 Transaction 31: Acquired SLock on file3
16:57:40.765495 Transaction 37: Acquired SLock on file3
16:57:40.766625 Transaction 42: Trying to acquire SLock on file2
16:57:40.766659 Transaction 42: Acquired SLock on file2
16:57:40.766795 Transaction 35: Released XLock on file1
16:57:40.766810 Transaction 36: Acquired XLock on file1
16:57:40.768930 Transaction 43: Trying to acquire XLock on file1
16:57:40.768911 Transaction 44: Trying to acquire SLock on file3
16:57:40.768977 Transaction 44: Acquired SLock on file3
16:57:40.771104 Transaction 36: Released XLock on file1
16:57:40.771126 Transaction 40: Acquired SLock on file1
16:57:40.771138 Transaction 29: Acquired SLock on file1
16:57:40.771587 Transaction 38: Released SLock on file3
16:57:40.772723 Transaction 42: Released SLock on file2
16:57:40.772962 Transaction 45: Trying to acquire SLock on file1
16:57:40.772983 Transaction 45: Acquired SLock on file1
16:57:40.772987 Transaction 45: Released SLock on file1
16:57:40.777529 Transaction 46: Trying to acquire XLock on file3
16:57:40.778095 Transaction 44: Released SLock on file3
16:57:40.778593 Transaction 31: Released SLock on file3
16:57:40.780857 Transaction 47: Trying to acquire XLock on file3
16:57:40.783901 Transaction 37: Released SLock on file3
16:57:40.783939 Transaction 39: Acquired XLock on file3
16:57:40.785097 Transaction 48: Trying to acquire SLock on file1
16:57:40.785149 Transaction 48: Acquired SLock on file1
16:57:40.785188 Transaction 29: Released SLock on file1
16:57:40.786138 Transaction 49: Trying to acquire SLock on file3
16:57:40.787325 Transaction 50: Trying to acquire XLock on file3
16:57:40.787376 Transaction 40: Released SLock on file1
16:57:40.795835 Transaction 39: Released XLock on file3
16:57:40.795931 Transaction 41: Acquired XLock on file3
16:57:40.798671 Transaction 48: Released SLock on file1
16:57:40.798710 Transaction 43: Acquired XLock on file1
16:57:40.806266 Transaction 41: Released XLock on file3
16:57:40.806295 Transaction 49: Acquired SLock on file3
16:57:40.813819 Transaction 49: Released SLock on file3
16:57:40.813873 Transaction 50: Acquired XLock on file3
16:57:40.815948 Transaction 43: Released XLock on file1
16:57:40.815980 Transaction 26: Acquired XLock on file1
16:57:40.817133 Transaction 26: Released XLock on file1
16:57:40.817174 Transaction 20: Acquired XLock on file1
16:57:40.827463 Transaction 50: Released XLock on file3
16:57:40.827472 Transaction 30: Acquired XLock on file3
16:57:40.836338 Transaction 20: Released XLock on file1
16:57:40.846663 Transaction 30: Released XLock on file3
16:57:40.846683 Transaction 47: Acquired XLock on file3
16:57:40.853782 Transaction 47: Released XLock on file3
16:57:40.853797 Transaction 24: Acquired XLock on file3
16:57:40.863729 Transaction 24: Released XLock on file3
16:57:40.863756 Transaction 46: Acquired XLock on file3
16:57:40.875885 Transaction 46: Released XLock on file3
Done!
If you look at the lines just pertaining to any individual file, you’ll see that the sequence of operations performed on it satisfy the invariants we expect: no SLock and XLock are held on a file at the same time, and only one XLock is held on a file at the same time.
If you were designing a database for specific use cases (like for more read-heavy workloads or more write-heavy workloads), then I imagine you could adapt this kind of stress test to compare how different locking strategies improve performance.
-
Go’s built-in map type isn’t concurrent safe. There’s a
sync.Maptype that can be used as an alternative, but it’s generally not recommended unless you have done performance testing to confirm it’s faster since it adds overhead in some scenarios. ↩ -
The way
wait()works in Java is it pauses the current thread, only waking it up once until either (a) a timeout expires, or (b) the thread is woken up by a call tonotify()ornotifyAll(). ↩ -
Specifically,
Object.notifyAll()it wakes up all threads that went to sleep via otherObject.wait()calls made by the same object. ↩ -
Alas, this implementation isn’t the most efficient, since multiple threads may be woken up by
notifyAll(), but it’s possible only one of them can re-acquire the lock. This isn’t too hard to fix, just requires a little bit of extra bookkeeping. ↩ -
They are also tricky to use properly. I really like the mental model of channels provided in this blog post, if you’re interested in learning more about them. ↩
-
This algorithm can be optimized a bit further to reduce how many goroutines are woken up in high-concurrency scenarios, but at the very least this gets the implementation working. ↩